





Introduction: AMD and Polaris 10: the RX 480.. Here we are, finally. After a bit of a wait (and some delay on our part), we’re ready to talk to you about AMD’s new GPUs, codenamed Polaris . The lineup, consisting of 2 GPUs and 3 video cards, for the moment, the AMD Radeon RX 480 , the AMD Radeon RX470 and the AMD Radeon RX460 .
Obviously, let’s start with the “leaders”, talking about the AMD Radeon RX480, based on AMD Polaris 10 “Ellesmere XT” GPU , that is equipped with the maximum number of CU (Compute Units), for a total of 2304 Shaders, combined with a bus from 256-bit versus 4 or 8GB of 7/8 Gbps GDDR5 memory.

Anticipating that in the coming days you will see our reviews of the RX470 and 460 , in the meantime we leave you to our review (accompanied by the complete analysis of AMD’s 4th generation architecture) of the AMD Radeon RX 480 . Enjoy the reading!
AMD Radeon RX480: technical specifications–
Below, the technical specifications of AMD’s graphics card. Further information can be found on the official website ( AMD ):

With a power greater than 5 TFLOPS (to be precise, 5.83 TFLOPS), the RX 480 is equipped with 36 CUs, each with 64 Stream Processors, for a total of 2304 shaders operating at a base clock of 1120 MHz , with a boost clock of 1266 MHz .
Available in 4GB and 8GB variants, the card has GDDR5 memory clocked at 7000 MHz and 8000 MHz respectively depending on the size of memory purchased, and the bus with which the GPU communicates with the memories is 256-bit.
The GPU used is the Polaris 10 , in its complete 36 CU configuration, also available in the 32 CU variant which acts as the calculation unit of the RX 470 , which today sees the release on the market.
AMD immediately spoke of the RX 480 as an economic card, with reduced consumption and adequate performance to play adequately in VR (Virtual Reality), guaranteeing a very fluid experience in Full HD and gaming in 2K at a framerate. more than decent, a goal that, as you will see from the benchmarks, has hit the mark.
The maximum consumption is about 150 W , and at the time of the launch of the card, which took place about a month ago, there were problems that theoretically would have jeopardized its operability in “safety” on particularly old motherboards, due to the excessive current draw through the PCI-E connector.
In the meantime, let’s clarify that the danger has never been as real as some other newspapers have suggested (and that all the “reports” of users who burned their mainboards were actually using old motherboards and various RX 480 used for mining ).
With the second driver release (i 16.7.1) AMD solved the power distribution, increasing the load on the PEG power connector and decreasing it on the PCI-e 16X socket, making it completely safe to use one (up to 4) cards on any motherboard.
150W, in relation to the consumption of the GTX 1060 (direct competitor, although the latter costs more), may seem a lot, but considering that we come from several generations of AMD graphics cards with a power consumption greater than 230-250W, this increase in efficiency can only benefit AMD’s reputation, which has always been labeled a manufacturer of power-hungry and thermally inadequate cards for the times.
The reference card has support for all AMD technologies, one of all FreeSync , with HDMI 2.0b and DisplayPort 1.3 connections , with support for the draft standard specification in version 1.4, which has not yet been finalized. However, there is no DVI connector, making it impossible to use the card (at least out-of-the-box) with 144 Hz screens, a problem that can be solved by purchasing HDMI to DVI adapters.
Polaris architecture: much more than GCN 4.0
Much has been said about AMD’s Polaris architecture and how it evolves in the next generation of GPUs, but don’t get it wrong: the so-called “fourth generation” doesn’t change any of the core principles of GCN (Graphics Core Next), simply updating a few elements. to increase performance with DX11, DX12, OpenGL and Vulkan workloads.
More importantly, it’s the incredible leap forward in efficiency, partially achieved thanks to Samsung’s new 14nm FinFET manufacturing process.

One of the main reasons we’re seeing a leap in efficiency with these new generations of GPUs (both from AMD and NVIDIA) is the shift to new manufacturing processes (14nm for AMD, 16nm for NVIDIA).
While until a few years ago it was possible to witness a reduction in the size of transistors on an annual basis, in 2011 the phenomenon reached a sudden stop. At the time, the 28nm manufacturing process was introduced but due to some obstacles faced by both sides, it has been difficult to achieve technological advances, mostly due to the huge volume of smartphone sales, taking away resources and time. market.
Although it was born as a particularly inefficient production process, with a high transistor density compared to the previous 40 nm (2009), the latest incarnations (Maxwell for NVIDIA, Granada and Fiji for AMD) were particularly power-efficient, thanks to the work of the engineers which have been able to optimize the power in relation to the surface, while at the same time decreasing the production of heat.
The 14nm, on the other hand, represents a huge leap in quality for AMD, which is now able to take advantage of the lessons learned with the 28nm architecture, improving it for the new “node”.
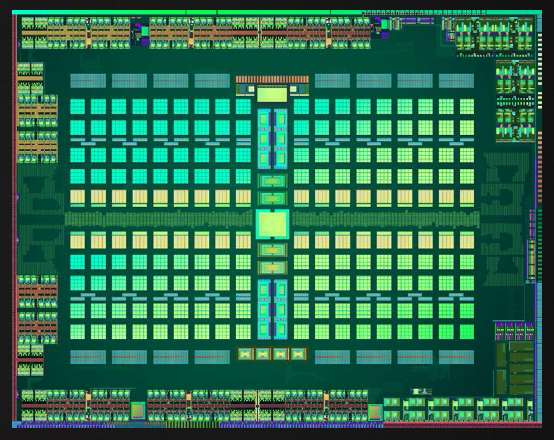
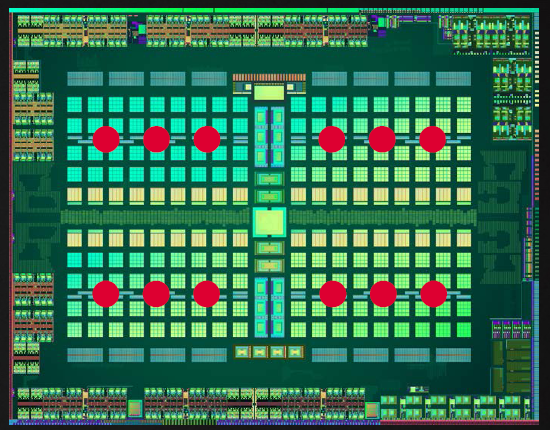
The fourth generation GCN architecture will be found, at the moment, on two chips: Polaris 10 and Polaris 11. For this review, we will take a look at the whole of the largest and most performing P10 chip, while we will talk about the P11 on the occasion of the review of the RX 460. In this iteration, Samsung’s 14nm FinFET production process (pp) (transistors are 3D, not planar) allowed to contain 5.6 billion transistors in a particularly compact die.
To make the comparison better, we have about the same number of transistors as the R9 390X in the graphics processor space of an HD 7790. Incredible, isn’t it?
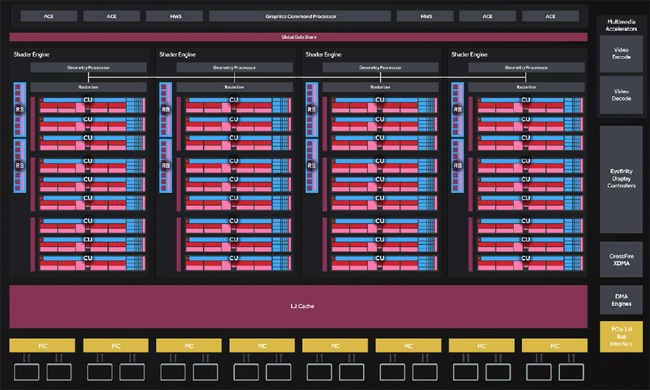
What do 5.66 billion transistors mean in a die of about 243.3mm²? Well, an architectural design that looks a lot like a slightly scaled-down version of a Hawaii Pro, but infinitely more efficient. One thing to note is that this is the “full size” version of Polaris 10, and therefore there will be no other “unlocked” or “revised” cards from this particular core.
From a high-level perspective, Polaris 10 hosts 4 Geometry Processors, each of which houses 9 of 36 Compute units, for a total of 36 CU. They are configured to work interconnectively through the use of a GCP, a Graphics Command Processors. If we exclusively analyze the design of the chip, there are not many differences with the previous iteration (the one used by Tonga and Fiji) of the new architecture, but it is under the “hood” that the changes capable of increasing the IPC are hidden (Instructions- per-clock, practically the computing power), where “micro” adjustments allow the increase of “macro” computing efficiency.
First, these changes include an improvement in the way each Geometry Processor handles the workloads for each block. Here, there is a huge generational leap obtained thanks to a better communication with the computing units, in order to eliminate the “dead” moments in the processing pipeline.
Polaris’ caching hierarchy also sees some drastic changes to its layout: the amount of L2 cache doubles to 2MB, practically doubling the amount found in Hawaii, and although some of the instruction caches have been “scattered” all over the die, the bandwidth has been improved and in some cases duplicated. This is especially important as increased caching efficiency removes some of the load from the 256-bit bus, which is divided into 8 32-bit memory controllers.
One of the areas that hasn’t seen many changes is the Back-End of rendering: although there have been some increases in the performance of each individual ROP, this area could represent a bottleneck, with only 32 ROPs instead of 64 as on the cards. based in Hawaii and above.
On a large-scale perspective, you will also notice that the block relating to the TrueAudio functions disappears , freeing up space on the die for greater computing efficiency in relation to the size of the chip. This function is now handled directly by the shaders, but we’ll talk about it in detail shortly. In addition, there is a new display controller with native support for HDMI 2.0b and DisplayPort 1.4, along with a heavily revised multimedia block (encoding and decoding of video formats, mostly).
Last but not least, the possibility of making firmware changes via driver, thanks to which it will be possible to “evolve” Polaris whenever new features are required. This procedure was used to change the current management of the phases and solve the power problem of the first days.
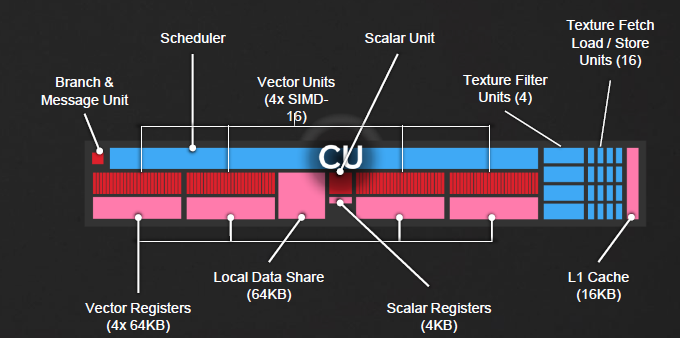
Many of Polaris’ changes have been made at the single Compute Unit level. As well as other GCN-based chips, each CU includes 64 Stream Processors divided into groups of 16, four 64KB register caches, 4 textures units with load and save functionality and one block of 16KB dedicated L1 cache.
AMD’s priority at this round has been to increase the inherent efficiency of each shader, and this has been achieved with an improved instruction prefetch algorithm. It improves efficiency by shortening pipeline “occlusion” and makes instruction caching smoother.
This also benefits single thread performance where workloads cannot be split as with DX12 or Vulkan, thus increasing performance with DX11 titles.
These improvements lead to an increase in performance clock per clock of about 15% compared to the R9 390, and this without considering the operating frequencies higher than the latter, obviously thanks to the transition to 14 nm.
Another addition is what AMD calls “Shader Intrinsic Functions”. They stem directly from AMD’s experience with the console market, and while they don’t have much to do with the Polaris architecture per se, SIFs could have a drastic impact on the future of Radeon GPUs. These extensions are essentially transported in full from consoles via an API library via GPUOpen, can be easily “ported” into the PC world, and can guarantee developers superior performance thanks to familiarity with similar architectures.
Hardware Scheduler rinnovato, Primitive Discard Accelerator e Color Compression–>
If you’ve read this far, it should be clear that Polaris is more than just another evolution for AMD’s GCN architecture. Instead, it represents a huge efficiency boost to pipelines that enable the current and next generation to speed up workloads. However, what we described on the previous page was just the tip of the iceberg.

As you may have noticed in recent weeks, AMD has always compared Polaris 10 to the R9 290 and 390, both from a performance and architectural point of view. Where Polaris differs from previous generations is the fact that one of the basic operating principles is “do more with less”. This is evident in the amount of ROPs, Shaders and Texture Units; there are fewer of them than there were previously, yet on paper the RX 480 is set to beat them in both efficiency and power.
This phenomenon is also present on the ACE (Asynchronous Compute Engines) front, since we find only 4 instead of 8 as in Hawaii, but in reality there should be an improvement in the architecture’s ability to process asynchronous workloads. Instead of a full allocation of ACEs, 2 of them have been replaced by dedicated Hardware Schedulers. These schedulers have the ability to commit a percentage or entire CUs for different purposes in a completely dynamic way.
This is the key for a correct temporal and spatial management of resources, for the planning of concurrent operations or processes in asynchronous computing and, perhaps more importantly, for the dynamic balancing of the load between the various computing units. You can imagine these new ACEs as Compute Engine “on steroids”, not so much for the greater power available as for the infinite dynamism with which it manages loads of a different nature.
This may sound a bit complicated, but the result is a significant increase in performance in asynchronous contexts and can also increase the granularity with which CUs can be controlled. With a hardware Scheduler, an entire CU or even a certain percentage of each CU can be dedicated to a specific task and scaled proportionally in a totally dynamic way.
For example, HWSs can use TrueAudio Next acceleration (which is now used for positional audio in VR applications) on a group of SIMDs or an entire CU depending on the resources required by a specific application. Put simply, it means that a smaller portion of the GPU will stand still and do nothing and this will increase performance.
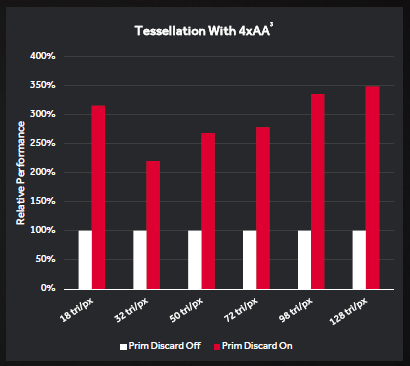
Another interesting addition is what AMD calls the Primitive Discard Accelerator. This new feature allows Geometry Engines to analyze the geometry of a particular scene and discard unnecessary textures and “triangles”, all at the beginning of the pipeline .
In practice, when the PDA is used correctly the GPU will not waste resources rendering elements that will not be seen by the player. This is especially important with the use of multi-sampling AA or any anti-aliasing that requires multiple passes and therefore, the performance gains are greater the higher the level of AA used.
There is also a new Index Cache which acts as a quick access point for smaller geometric instructions. Essentially, this cache limits the amount of information moving from one pipeline to another, freeing up internal bandwidth. Combined with the PDA, Polaris 10 can theoretically offer up to 3.5 times the performance of the previous generation.
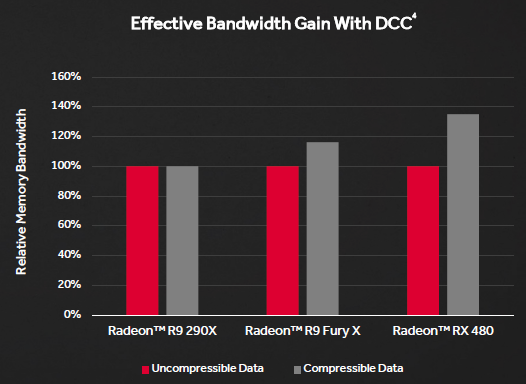
While GDDR5 may not offer the bandwidth benefits of HBM or GDDR5, AMD has still found a way to increase throughput without adapting the architecture to a more expensive memory standard. Without even increasing the bus width (thus occupying a larger area and, therefore, generating more heat), the only step to take was to improve the color compression algorithms, in an attempt to increase efficiency rather than simply raise the theoretical maximum band.
Previous architectures (Fiji and Tonga, especially) already included some sort of color compression, but Polaris raises the bar by boasting native support for compression ratios of 2: 1, 4: 1 and 8: 1.
Although the Radeon Technology Group formally admits that there is still a long way to go to get to the level of NVIDIA’s DCC, Polaris represents a huge step forward in bridging the gap between the two companies in this regard.
At present, in fact, AMD’s DCC algorithms allow a relatively small bus of 256 bits to have performances very close to that of the previous generation 512.
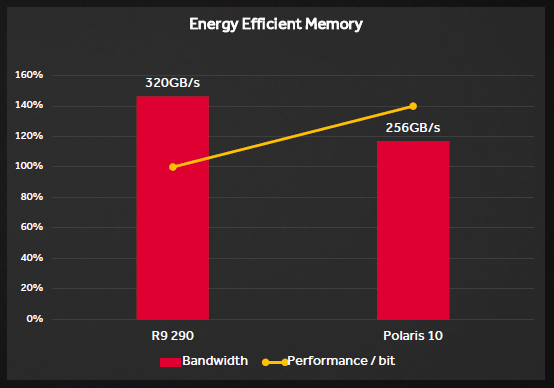
Together with the enormously improved L2 caching hierarchy and DCC’s new improved algorithms, the Polaris memory interface may not have a huge amount of bandwidth, but it is extremely efficient. Presumably, the performance increase per bit is about 40%, which allows both significant energy savings and better use of resources by developers.
Efficiency, 14nm and beyond–>
In AMD’s relentless mission to optimize the efficiency of their CPUs, GPUs, and APUs, there have been as many successes as there have been failures. However, we have come to the point where the technological advances of one category flow into another. This “graft” has led Polaris to incorporate many power saving features typical of APUs.
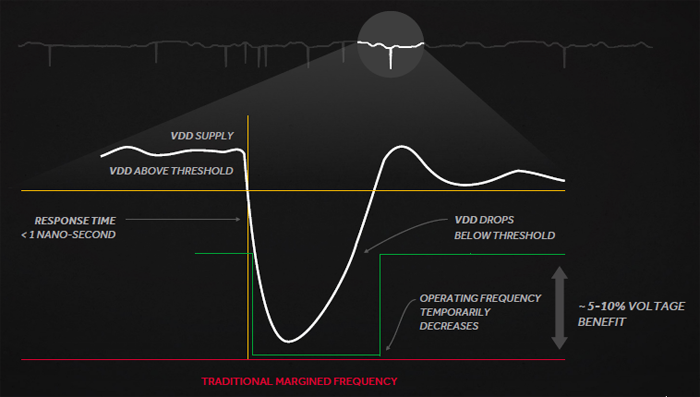
One such technology is defined by AMD as “Adaptive Clocking”. It allows to have higher amperages at lower voltages, minimizing the vDrop. In this case, the frequency can be dynamically balanced to equalize voltage fluctuations almost instantaneously, resulting in higher operating frequencies, as AMD’s engineers don’t have to stick to the common minimum voltage.
Adaptive Clocking leads Polaris to maximize performance at lower voltages, resulting in significant energy savings. It exists within the PowerTune algorithms themselves, making it totally transparent to the end user.
Like the Carrizo and Bristol Ridge APUs (recently introduced), Polaris senses voltage, current and temperatures from different points on the GPU. The so-called Adaptive Voltage and Frequency Scaling not only help the architecture to “extract” the maximum frequency at all times, but also determine an excellent operating range before one of the tresholds (the temperature, voltage and / or current limits imposed) are exceeded. They also take preventative action, so the extreme frequency fluctuations seen so far are just a ghost of a past Christmas.
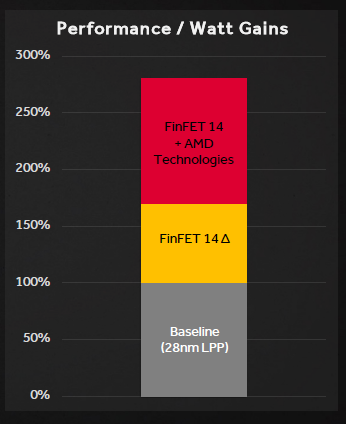
All of these elements only scratch the surface of what Polaris has to offer in terms of energy savings, and the overall benefits are significant. AMD has estimated that the transition to a new production process affects only 70% of the new performance / watt ratio, while a further 110% has been obtained through the use of the aforementioned technologies described so far and improved resource driver management. The end result is a 2.8 times higher performance / W ratio, which is impressive beyond belief.
Test configuration and test methodology–>
The configuration used for the tests is as follows:
Here is the suite of benchmarks (and games) with which we will test the video card:
- Unigine Heaven Benchmark 4.0 (DirectX11)
- Futuremark 3DMark Fire Strike (DirectX11)
- Futuremark 3DMark Fire Strike Extreme (DirectX11)
- Futuremark 3DMark Fire Strike Ultra (DirectX11)
- Futuremark 3DMark Time Spy (DirectX12)
- Bioshock Infinite (Integrated Benchmark) (DirectX11)
- Metro Last Light (Benchmark integrato) (DirectX11)
- Middle-earth: Shadow of Mordor (Integrated Benchmark) (DirectX11)
- Grand Theft Auto V (GTA V) (Built-in benchmark, average of 5 scene results) (DirectX11)
- Rise of the Tomb Raider (Benchmark integrato) (DirectX12)
- Hitman (2016) (Integrated benchmark) (DirectX11 and 12)
- Doom (2016) (First level, immediately after the start of the game) (Vulkan)
- Ashes of the singularity (Benchmark integrato, Crazy Preset) (DirectX11 e 12)
Where resolution choice available, tests were performed at the following values. Where it was a benchmark, the default modes were used:
- 1920×1080, AA x4 (Full HD)
- 2560×1440, no AA (2K, QWHD)
- 3840 × 2160, no AA (4K, UHD)
Test sintetici: Unigine Heaven 4.0 (DirectX 11
Heaven , produced by Unigine was the first DX11 Benchmark. The main purpose is to highlight the extraordinary effects of Tessellation. In fact, from the simple observable models with deactivated tessellation, we arrive at objects rich in depth and protrusions without having to create complex textures.
The task of enriching the model is left to the tessellation unit, so it is an indispensable tool for evaluating the efficiency of this unit in modern DX11 solutions:
Test sintetici: FutureMark 3DMark Fire Strike (DirectX 11) e Time Spy (DirectX 12)
In conjunction with the launch of Windows 8, Futuremark has launched the new 3DMark , called precisely 3DMark, without any recognizing number, to mark the strong integration it has with any system, from Android to Windows to iOS to OSX, giving for the first time the possibility of comparing the performance on smartphones and desktop PCs in a schematic and professional way. The benchmark has several tests, of which we use the most intensive to test video cards.
Among these, the most challenging is the Fire Strike , which pushes tessellation to really high levels, and which “boasts” two even more extreme versions: Extreme (with pre-rendered scenes at 2560 × 1440) and Ultra (pre-rendered scenes. at 3840 × 2160, i.e. 4K).
Recently, however, the Time Spy benchmark was introduced , which tests GPU performance using the new Microsoft DirectX 12 API, with pre-rendered scenes at 2560 × 1440:
Game Test: Bioshock Infinite (DirectX 11)
We continue with Bioshock Infinite , which puts us in the shoes of Booker DeWitt , a private investigator, once Agent Pinkerton, in charge of finding a girl, Elizabeth, held captive in Columbia , a mysterious city suspended in the skies, where genetic modifications are considered true. and own luxury goods. For the first time in the BioShock series, the character has a face, a name and a story prior to the game, which will be revealed as the game progresses.
The game supports the DirectX 11 API, with which it supports technologies such as: High Definition Ambient Occlusion , Contact Hardening Shadows and Diffusion Depth of Field . FXAA (Fast Approximation Anti-Aliasing) support optimized for use on SM 5.0 is also implemented. The game is optimized for AMD architectures , as part of the AMD Gaming Evolved program .
Game Test: Metro Last Light (DirectX 11)
After the incredible success of Metro 2033 , here is its successor, Metro Last Light , based on the novel Metro 2034 by Dmitry Glukhovsky, which sees the world struggling with the aftermath of a third atomic world war. , with all that goes with it: the living population in Russia has moved to the infamous Russian metro, equipped with 298 km of tracks and tunnels under Moscow.
Once again, the player will take on the role of Artyom, to prevent a civil war that could bring mankind to an end. Technically speaking, the game is incredibly heavy , both for screen polygons and requirements, making use of all the technologies introduced by DirectX11 : Depth of Field, HDAO, Tessellation and real-time Motion Blur. The game is optimized for NVIDIA video cards , given support for N VIDIA PhysX and as part of the NVIDIA program – The Way It’s Meant To Be Played .
Test sui giochi: Middle Earth: Shadow of Mordor (DirectX 11)
Those who are passionate about the JRR Tolkien saga know that, until September 2014, there was no game worthy of the name that would narrate the events of Middle Earth. Thanks to Monolith and Warner Studios, however, now the most famous fantasy series in the world boasts a triple A game, with an overwhelming plot, graphics on the edge of photorealism and a combat system that seems to be the evolution of the Free Form. Fighting System seen in Prince of Persia: Warrior Spirit. The result?
A must-have title, whose graphics engine is based on the one used by Batman: Arkham Origins , a title it replaces in our suite of benchmarks. The game is optimized for NVIDIA video cards , given support for HBAO, SMAA and more generally all the company’s GameWorks . The game, especially at high resolutions and with maximum filters, requires a considerable amount of video memory, and therefore is fully indicated if you want to test video cards with a greater quantity of VRAM:
Test sui giochi: Grand Theft Auto V (DirectX 11)
Grand Theft Auto . A saga that has its roots in blood and violence in top view and 2 dimensions, and that in the last iteration, expected for 8 long years by PC users. In 2015, after 8 years of waiting (for PC users), GTA V saw the light on the computer screens of all gamers, breaking record after record in sales and profits.
A totally different approach, the one for the story: three controllable characters, each crazier than the other, between the mafia, shootings, explosions and spectacular robberies. The game is optimized for NVIDIA video cards , featuring support for all of the company’s GameWorks except Hairworks . At high resolutions, the game is a real battleground where you can test the most powerful video cards:
Test sui giochi: Rise of the Tomb Raider (DirectX 12)
Lara Croft makes her return in the second reboot title of the Tomb Raider saga , in The Rise of the Tomb Raider (or RotTR if you like acronyms), one of the first DirectX 12 games to see the heroine of our lonely afternoons raiding graves around the world, trying to solve the mystery behind his father’s death.
The game is optimized for video cards NVIDIA , submitting your support to all GameWorks company except for Hairworks , replaced by PureHair , technology derived directly from standard TressFX of AMD , and uses both DirectX 11 and DirectX 12 and Async Computing for rendering:
Game Test: Hitman (2016) (DirectX 12)
Yet another reboot, and this time it’s Agent 47 who sees a “rebirth”, with Hitman (2016), which sees us grappling with a younger, colder Agent 47, grappling with several “episodes” (and it’s just the sales model of the title, episodes that are published over time) and various targets to kill, as per tradition.
The game is optimized for AMD video cards , presenting support for DirectX 12, Async Computing and SSAO, obviously also supporting DirectX 11:
Game Test: Doom (2016) (Vulkan)
Probably short of ideas, Bethesda joins the slew of software houses that in recent years has produced yet another reboot / remaster / remake of famous titles. This time it’s up to Doom , the infamous First Person Shooter, who in 1993 marked (together with Wolfenstein 3D) the birth of the 3-dimensional games that we love so much today. In contrast, the reboot of the series is not below expectations, and features a lot, a lot (maybe too much? Nah, it’s never too much) blood, with Epic Kills and many demons to kill.
The game is optimized for AMD video cards , and unlike the rest of the games on the market, it operates via OpenGL API , and, more recently, Vulkan , which provide an incredible advantage to the latest generation GPUs:
Test sui giochi: Ashes of the singularity (DirectX 12)
Breaking the trend of reboots and remakes of ancient games, Ashes of the Singularity is what Stardock (the software house behind the game) defines as a strategic game of planetary warfare , and with its huge maps and thousands of units on screen during full-scale fights, you can’t help but agree with the company.
What is often associated with Ashes is the incredible burden it applies to graphics systems (and beyond, the game is ravenous for cores and GHz), through the use of DirectX 11 and 12. The Crazy preset is able to put on its knees any GPU on the market already at Full HD resolution. The game uses support for AMD technologies , taking its cue from the Nitrous graphics engine used in one of the first benchmarks for Mantle , Star Swarm :
WattMan, overclock, temperature–
With Polaris, AMD introduces a new control panel within the Radeon Crimson Drivers , called WattMan (literally, the Watt man). Below is the interface of the management panel:
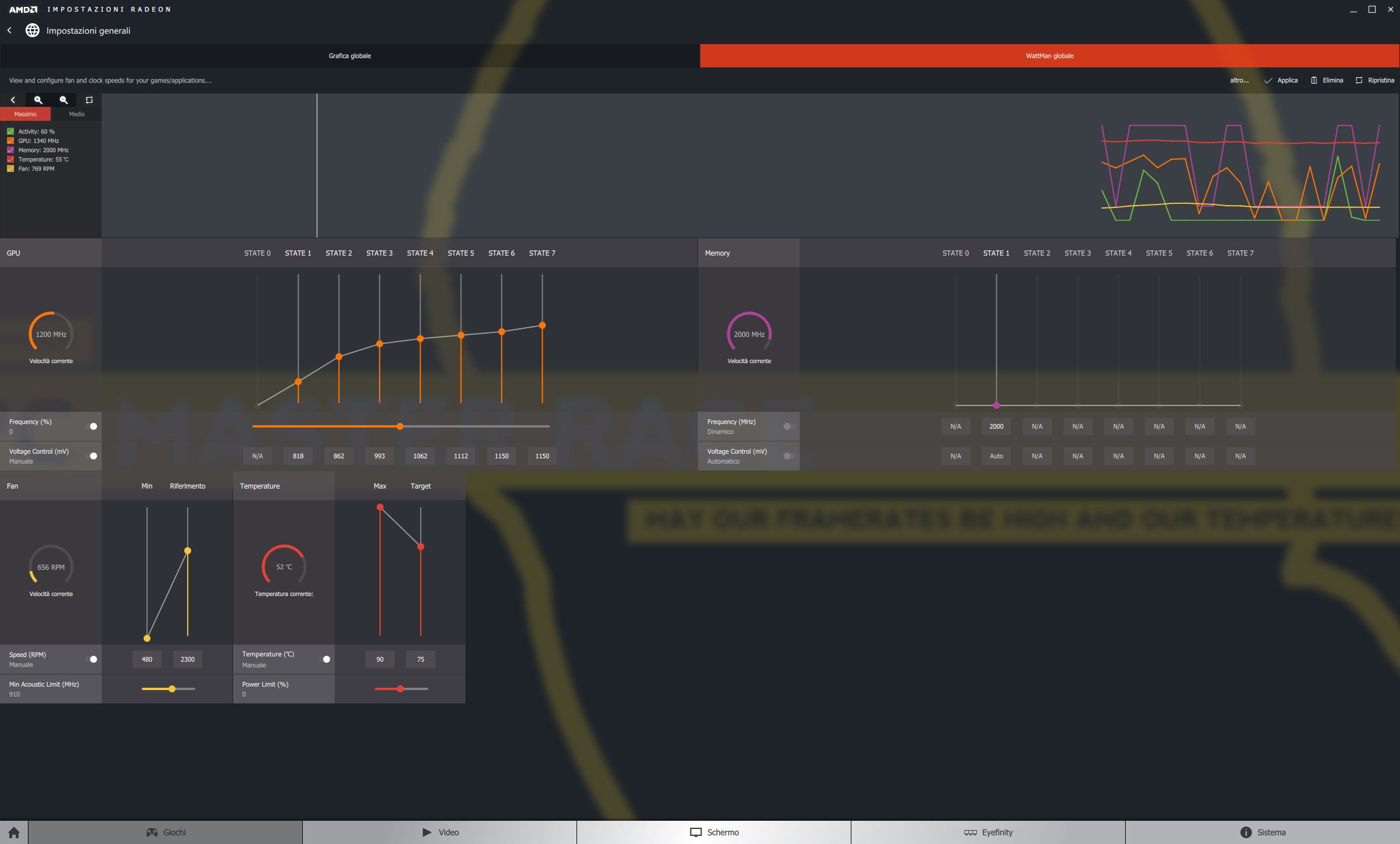
( editor’s note : the screenshot was captured with a Sapphire RX 480 Nitro + OC 8GB, it’s not the reference model) As is evident, compared to the old AMD Overdrive control screen, the company has taken a much more serious and methodical approach to overclocking and overvolting of your GPUs.
Since a two-axis graph for all the aspects that relate to thermal management, power and frequencies is passed to a series of menus that share the task of managing the frequency and voltage according to the various State (Think of them as SpeedStep Intel, which dynamically adjusts the frequencies according to the type of use), allowing greater flexibility in terms of managing the overclock, overvolt (or even undervolt) and the fan speed of the reference heatsink (which we remember to be of the blower type).
It is now possible to set a temperature target on which the GPU will automatically adjust itself through the PowerTune algorithms , obviously setting a maximum ceiling and adjusting the electrical and thermal specifications accordingly. With this generation of GPUs, AMD introduces its Boost Clock concept , which we see on NVIDIA cards for several generations (GTX6xx series onwards), which sees the card oscillate between the minimum clock of 1120 MHz and the maximum clock of 1266 MHz. Unlike NVIDIA, however, the card will not try to find the maximum stable frequency given the conditions of temperature, voltage and power limit, but will simply brick at the aforementioned 1266 MHz.
Honestly, rather than overclocking a reference card , equipped with an inefficient heatsink (and particularly noisy if pushed beyond factory values), I wanted to experience what many users on the subreddit / r / AMD have tested extensively: the undervolt. .
As already mentioned above, the card has higher consumption than the competition, thanks to the fact that AMD has done little binning on the GPUs used for the cards: in fact, it was found on a fairly large sample that all the GPUs operate at the same voltage, not therefore operating on the basis of the specifications necessary for stability, but instead carrying 7-15% higher voltages.
The result? In our case, the decrease with which the card was still perfectly stable is 67 mV (7%, considering that by default the card operated at 1087 mV), thus bringing it to exactly 1.02 V and thus lowering consumption and heat.
Furthermore, since the PowerTune acts on the basis of the detected values, a lowering of the generated heat and consumption has led the GPU to almost always use the maximum frequency of 1266 MHz, removing any danger of throttling .
We could also have overclocked our sample, but we prefer to leave that to the custom models ( we’re working on the review of Sapphire’s 8GB Nitro + OC ) the daunting task of pushing Polaris 10 beyond the factory limits.
Below, the temperatures measured:
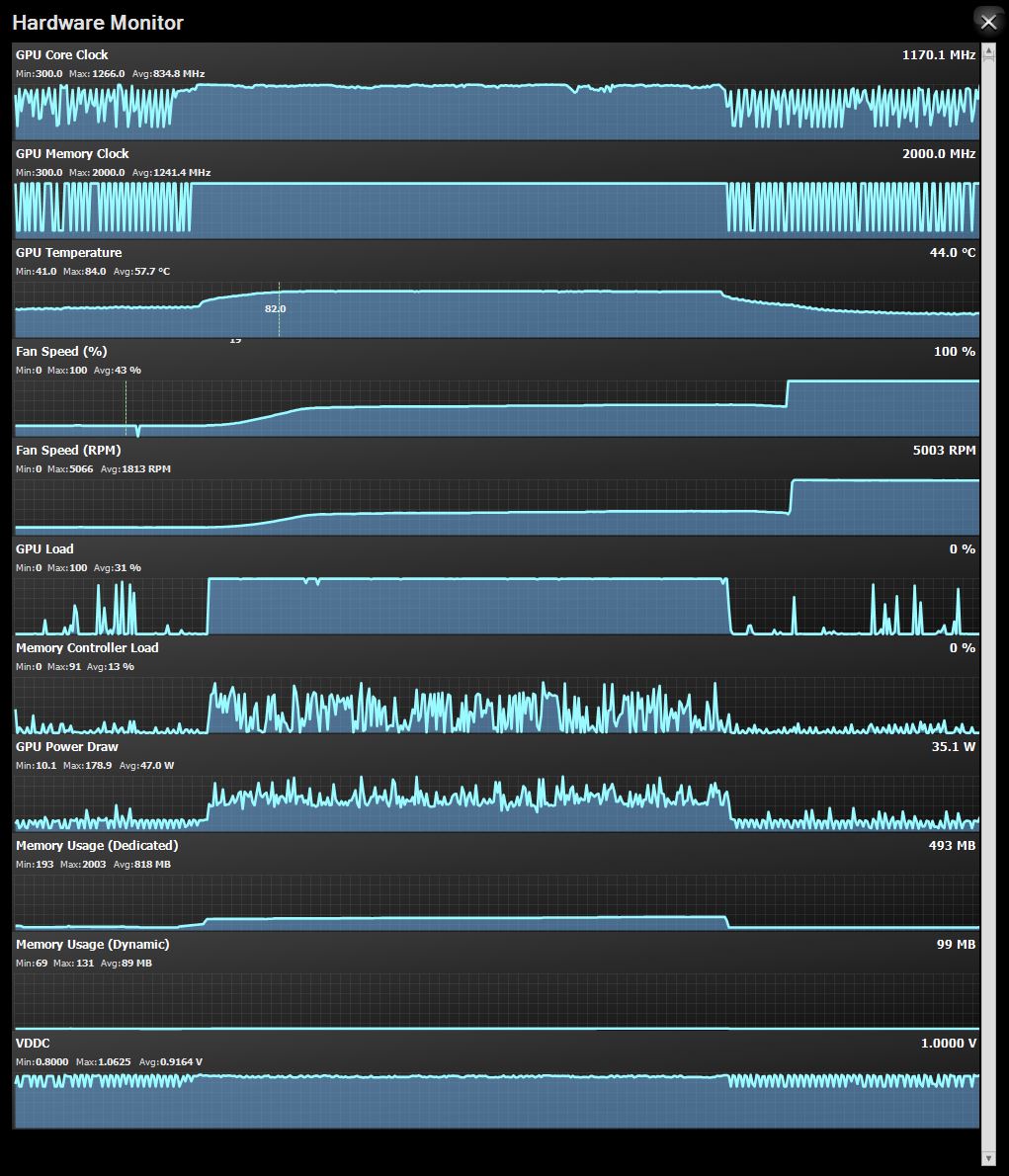
As you can see, the minimum temperature, with a T.Amb. of 32 ° C, it is 41 ° C , while the maximum is 84 ° C . These values were found when running Heaven 4.0 in 4K and maximum graphics settings. By bringing the fan to 100%, and thus touching well 6000 RPM , we dropped to 68 ° C , with acoustics that are difficult to sustain for long periods, even with headphones that isolate from external noise with moderate listening volumes. In short, if you want a fresh GPU, perhaps you need to aim for a custom model and not the reference one.
The peak consumption detected by the TriXX 6.0 is instead of about 180 W, exceeding the 150 W of Typical Board Power reported by the company.
Final thoughts
In conclusion, AMD’s Radeon RX 480 is an excellent starting point for what will be the custom models of the various AIB partners ( and we have Sapphire’s Nitro + OC model in our hands, we know what we’re talking about ). That said, we give the board our Hardware Platinum Award along with the Best Price Award for the incredible price / performance ratio:
We thank AMD and Edelman Italia for the sample reviewed today.
For today it’s all from ReHWolution , don’t forget to follow us on our social networks:
The review
AMD Radeon RX480 Polaris Reference
Pro
- Advanced support for the new DirectX 12 and Vulkan libraries
- Economic
- Performance between the R9 390 and R9 390X
- Lower consumption compared to the previous generation …
Against
- … but still superior to the competition
- Reference heatsink that leaves something to be desired
Summary of the review
- Design and build quality
- Performance
- Compatibility and consumption
- Price
Related posts:
 Bitmain Antminer r4 Review – Benefits Profitability Payback Specification
Bitmain Antminer r4 Review – Benefits Profitability Payback Specification  Nvidia GTX 1080 ti Hashrate – Review | Overclocking |Ethereum |Profit (sky high)
Nvidia GTX 1080 ti Hashrate – Review | Overclocking |Ethereum |Profit (sky high)  Antminer S5 ASIC Hashrate – Review Profitability Payback Period
Antminer S5 ASIC Hashrate – Review Profitability Payback Period  Asic Antminer S1 Hashrate – Review | Test| Specs| Pros & Cons | Set-up|
Asic Antminer S1 Hashrate – Review | Test| Specs| Pros & Cons | Set-up|  Miner Baikal Giant x11 – Hashrate|Profitability| Specs
Miner Baikal Giant x11 – Hashrate|Profitability| Specs  Radeon Hd 7970 Hashrate -Review|Profitability | Specs | Pros and Cons
Radeon Hd 7970 Hashrate -Review|Profitability | Specs | Pros and Cons


