





First technical details about the Alchemist architecture from Intel
: Test |CUP | Specs |Config
Intel has announced the first technical details on the Alchemist architecture, on which the GPUs of the Intel Arc series gaming graphics cards will be based. Even if tangible key data or benchmarks are still missing, it becomes clear in which direction the technology is going – and how much Intel has oriented itself towards Nvidia.
There will be multiple Alchemist GPUs
Anyone who expects the complete presentation or even benchmark results here and now will be disappointed. That was after the announcement that the first products of the Arc series will not appear until the beginning of 2022, but not to be expected either. Nonetheless, Intel had some news in its luggage at an event in Berlin on Wednesday.
Intel confirmed that there will be more than one GPU (Intel calls it SoC) based on the Alchemist architecture. These are not manufactured by Intel itself, but by TSMC in the N6 process and thus in a more modern production process than AMD’s RDNA-2 generation (N7P). So far nothing is known about the size and complexity of the chips, but a little bit about what it will look like under the hood. The Alchemist architecture is also essentially an Xe derivative, even if it doesn’t look like it at first glance.
Alchemist carries Xe within him
Because Intel has changed the naming of the individual elements for Alchemist in order to make it clear that the architecture differs from the previous IGPs, but remains essentially exactly with this term.
The rough structure is very similar to that of AMD and Nvidia
The heart of the Alchemist architecture is the Xe-Core, which Intel baptized for the first time. The Xe-Core is the equivalent of a streaming multiprocessor at Nvidia (SM), a Compute Unit at AMD (CU) or a Subslice according to Intel’s old nomenclature (EU).
The Xe-Core consists of 16 vector engines, which in turn are divided into 8 groups of 2 vector engines each. Intel has not yet revealed what the Vector engines look like. For example, Intel has not yet given the number of “Execution Units”, i.e. the individual FP32-ALUs in the engine.
If you start from the speculated 4,096 FP32-ALUs for Intel’s future Arc flagship and superimpose the currently known Alchemist structure, a Vector engine would have to consist of 8 FP32-ALUs and a Xe-Core would have to consist of 128 FP32-ALUs. That would be twice as many as in a CU from AMD RDNA 2 and exactly as many as in Nvidia’s SM on amps.
Intel’s XMX are Nvidia’s tensor cores
There is also a separate matrix engine for each Vector engine, which takes care of the acceleration of matrix calculations – according to Nvidia’s naming, a matrix engine is simply a tensor core. Intel christened it XMX-Core. 16 XMX cores are provided for each Xe core in Alchemist, so there could be up to 512 such units in the flagship GPU (Nvidia GA102: 328 “3rd Gen”).
Xe SS is Intel’s DLSS
Intel’s own AI upsampling XeSS (more details) will run on the matrix engine, and other AI applications can also be accelerated.
Last but not least, a Xe core also consists of load / store units and an L1 cache. Four Xe cores are combined in Alchemist into a so-called render slice, which Intel previously called simply Xe slice. With AMD, a render slice can best be compared with a shader engine, with Nvidia with a graphics processor cluster.
In addition to the Xe cores, a render slice contains two pixel backends with 8 units each and thus 16 ROPs, which probably amounts to 128 ROPs with a fully activated GPU (Nvidia GA102: 112). In addition, there is a rasterizer, a geometry unit and 4 “sampler units” with 8 units each. These are probably the texture units, which would amount to 32 TMUs per render slice and probably a maximum of 256 TMUs (Nvidia GA102: 328) on the GPU.
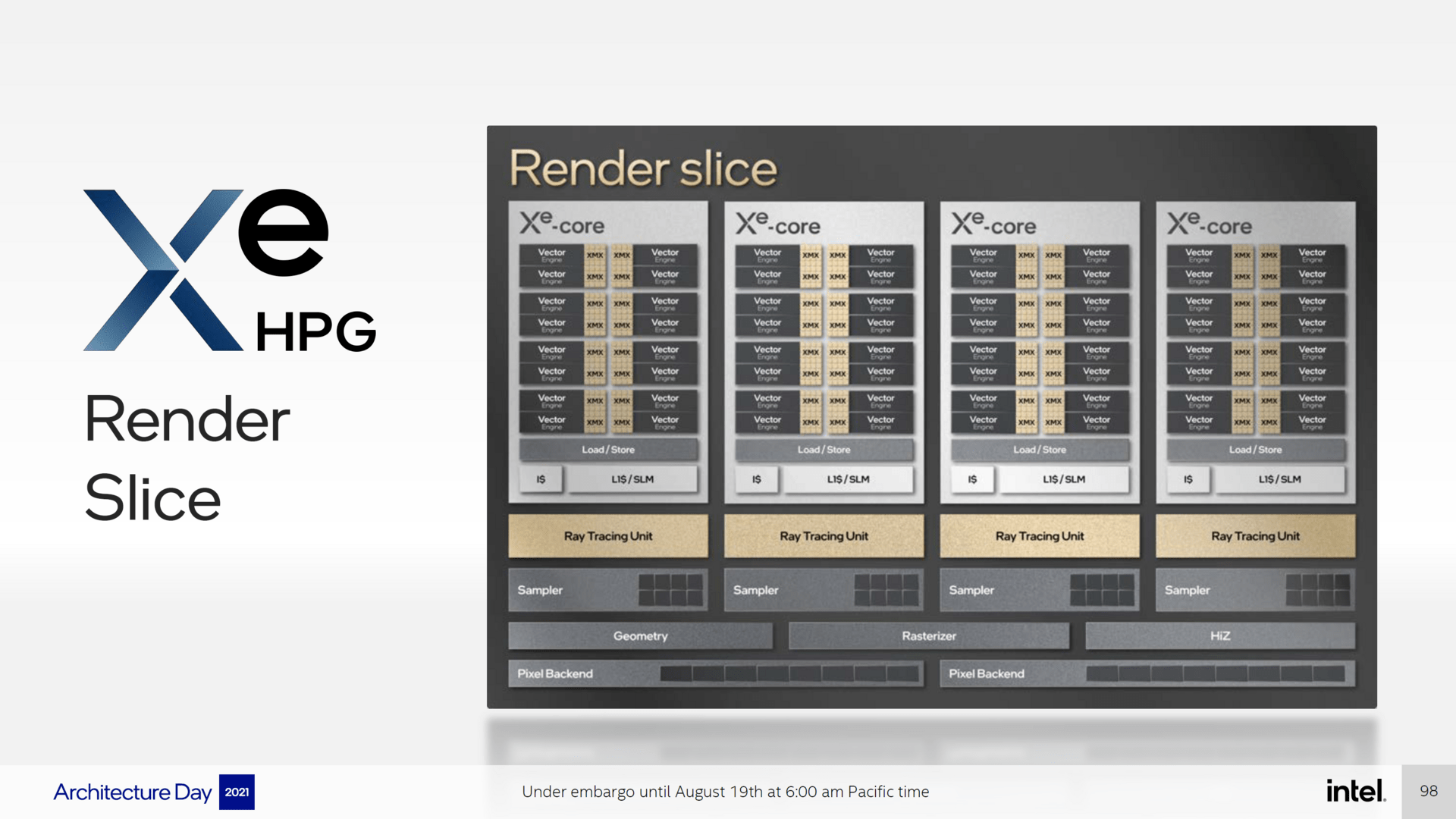
Separate ray tracing units with a lot of acceleration
Since Alchemist is a DirectX 12 Ultimate architecture, it must also be possible to accelerate ray tracing in hardware, which the previously available Xe GPUs were not yet able to do.
A render slice on Alchemist now again has 4 RT units, which are separate units like Nvidia. The probably maximum of 32 RT units (Nvidia GA102: 82) can accelerate the ray traversal, the triangle intersection and the bounding box intersection, which means that Intel’s RT units should definitely be superior to those from AMD, because they take care of them just about the ray traversal and the triangle intersection.
Nvidia’s RT unit also takes care of the creation of the complete BVH structure (excursus: Ray tracing in games VI: How beams are accelerated by GPUs), part of which is also the bounding box intersection calculation mentioned by Intel. Whether Intel’s RT-Core, like Nvidia’s RT-Core, will take care of the complete creation of the BVH structure is currently still unclear, but ComputerBase is currently assuming this and will try to receive confirmation as soon as possible.

Ray tracing acceleration on Alchemist (Image: Intel)
image 1 Of 3


Top GPU model with 8 render slices
Since a render slice would not provide enough computing power for a gamer’s graphics card, Intel can use eight of these in the fastest Alchemist expansion stage. That would make 512 vector and matrix engines and 32 RT units. These are supplied with data by a global dispatch unit and can communicate with one another via an L2 cache. The latter is connected to the render slices by means of a high bandwidth memory fabric. This probably also applies to the memory interface, but Intel is still silent on this.
50% more performance per watt than DG1
Intel has not yet made any statements about the performance, but the energy efficiency has been briefly commented on. According to this, Xe-HPG (High Performance Gaming alias Alchemist) should deliver 50 percent more performance per watt than Xe-LE (Low Energy) in discrete form and thus as a DG1 graphics card. This is made possible by the fact that a 50 percent higher cycle should be achieved with the same voltage. However, since there is little experience with the desktop DG1, it is difficult to classify this information correctly.
Intel has not yet given any further details on the Alchemist architecture. Since the market launch is delayed to the 1st quarter of 2022, there is still enough time to bridge the gap until the release.
According to Alchemist, according to Intel, the architectures Battlemage as Xe² HPG, Celestial as Xe³ HPG and Druid as Xe⁴ HPG are to follow, but there is still no speculation about these.
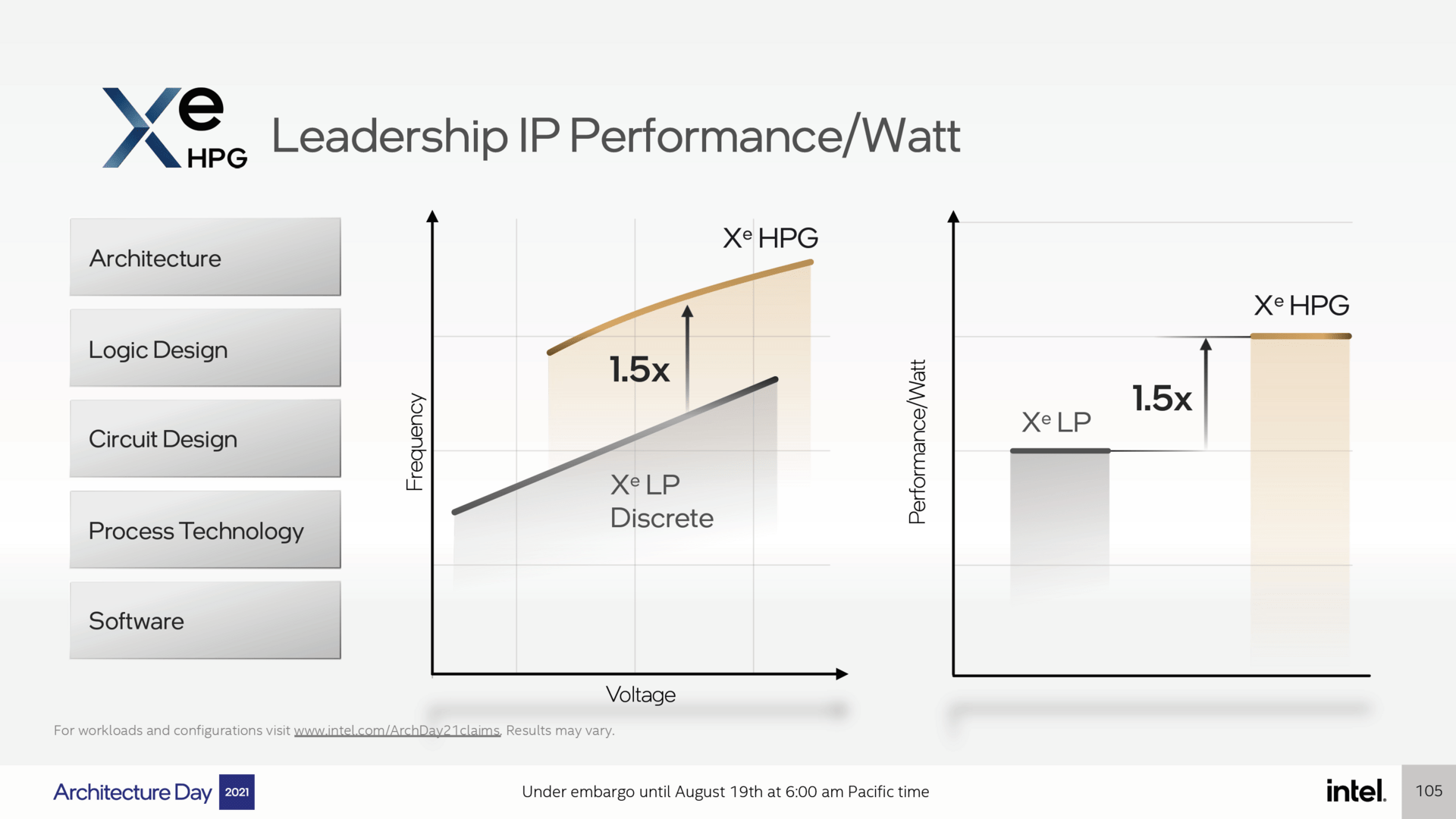
Better energy efficiency from Alchemist (Image: Intel)
image 1 from 2

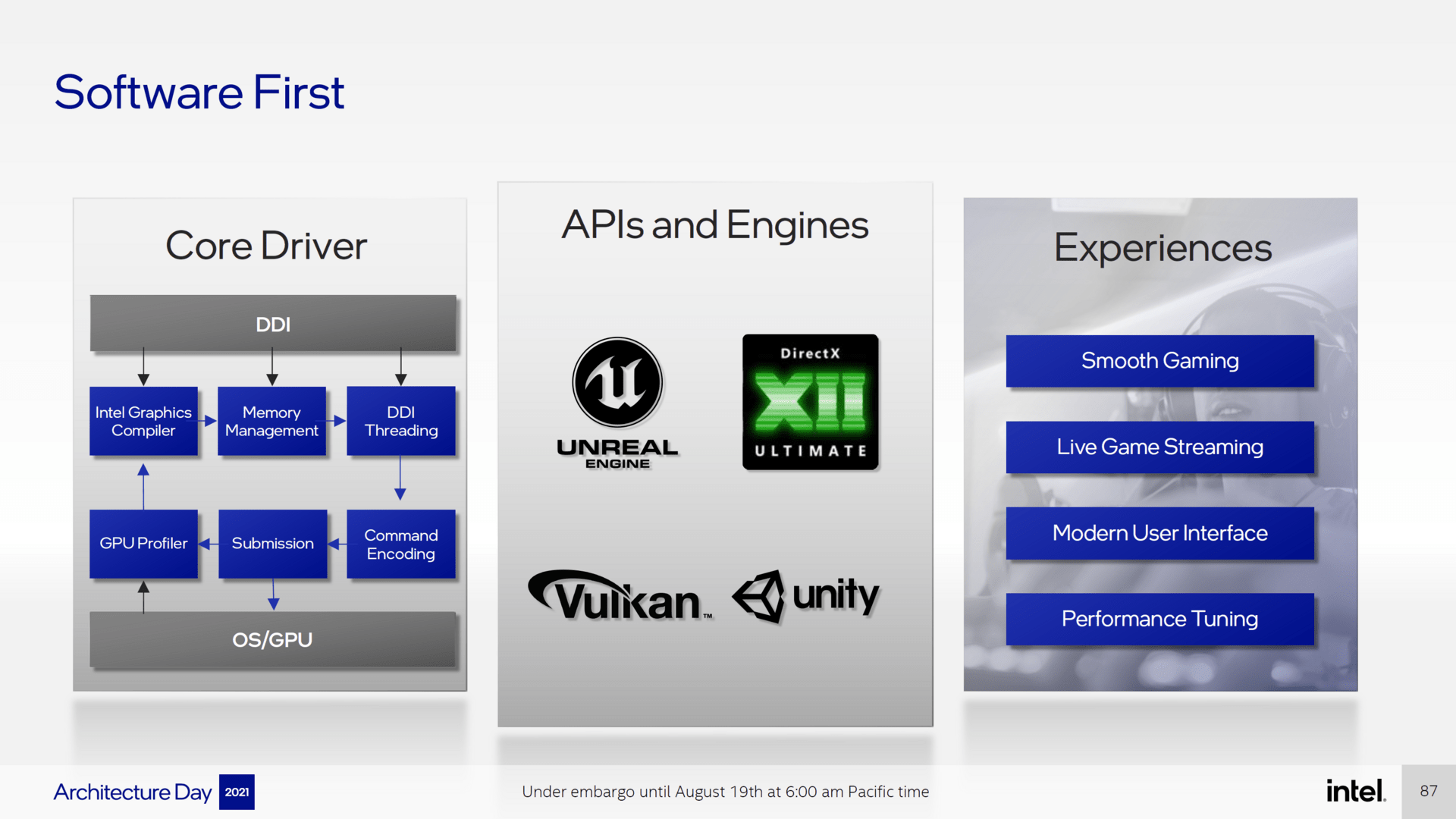
Details about the driver and new driver features
Intel has not only massively changed the hardware for the new graphics cards, the drivers are also said to have been revised. They want to have the “core driver” completely revised in order to be able to raise the performance and stability to a new level compared to the previous drivers. The new driver should, for example, increase the throughput in CPU-limited scenarios by up to 80 percent and reduce the loading times of games by 25 percent. In addition, there are said to have been numerous optimizations to accelerate common gaming workloads.
In addition to the driver, the driver interface is said to have been completely revised. In addition to a new user interface, there is now the option of game streaming. Enthusiasts should also have the option of overclocking the graphics card in the driver menu. This is reminiscent of AMD’s WattMan.
ComputerBase received the information for this report from Intel in advance at an event in Berlin under NDA as part of the Architecture Day 2021. The manufacturer did not exert any influence on the reporting, and there was no obligation to publish. The only requirement was the earliest possible publication date.
Was this article interesting, helpful, or both? The editors appreciate every support from ComputerBase Pro and deactivated ad blockers. More about advertisements on ComputerBase.
Related posts:
 7-nanometer Nvidia GPU, TSMC will handle most of the production
7-nanometer Nvidia GPU, TSMC will handle most of the production  ASRock X299, a new BIOS allows you to install 2 TB of memory
ASRock X299, a new BIOS allows you to install 2 TB of memory  MSI Prestige X570 Creation Review: Test | Specs | Hashrate
MSI Prestige X570 Creation Review: Test | Specs | Hashrate  Radeon RX 5500 XT, PCI Express 3.0 castrates performance?
Radeon RX 5500 XT, PCI Express 3.0 castrates performance?  An overclocker ran 1TB of RAM on an X299 motherboard limited to 256GB
An overclocker ran 1TB of RAM on an X299 motherboard limited to 256GB  Best Review 2021: MSI MPG X570 Gaming Edge WiFi Under $250 ($200)
Best Review 2021: MSI MPG X570 Gaming Edge WiFi Under $250 ($200)


