



This time, OpenAI created a system better than people in the retro game Montezuma Revenge, thanks to the newly developed RND method.
OpenAI is a San Francisco-based non-profit organization that has garnered the support of many investors, including Elon Musk. The scientists there mainly deal with the development of artificial intelligence, the achievements of which are revealed mainly in computer games. They already have a phenomenally successful team in DOTA 2, or a fratricidal team in Starcraft 2. In the latest project, they made sure to beat people in the old-school Montezuma Revenge game with Atari 2600. It is not difficult to guess that OpenAI was successful here, too, which, however, required a new approach to machine learning.
This is the RND (Random Network Distillation) method, or colloquially translated “random network distillation”. This can drive any machine learning algorithm that, for example, is based on a system of rewards and punishments that guide the actions of AI agents. Contrary to the traditional method, RND introduces an additional reward, based on predicting the result of a fixed and randomly initiated neural network in the next state. Thanks to this, the AI was encouraged to explore areas of the map that were not necessary to complete the game. Result? Discover all hidden rooms on the longest attempt and score an average of 10,000 points.
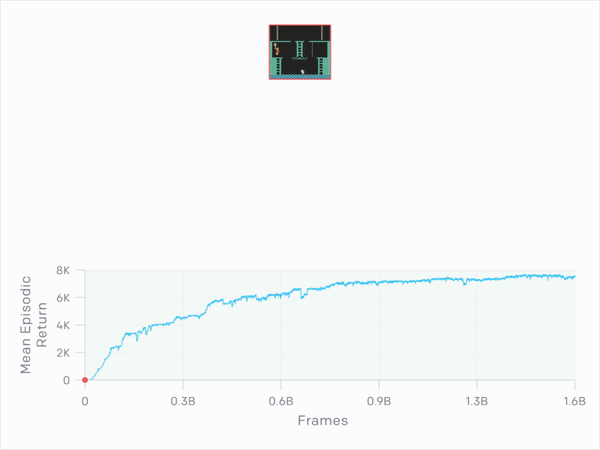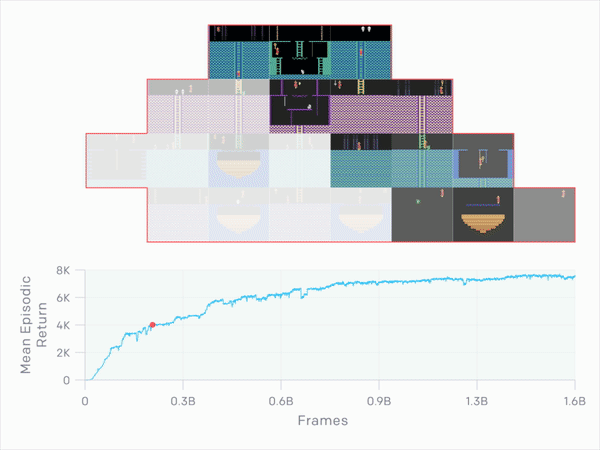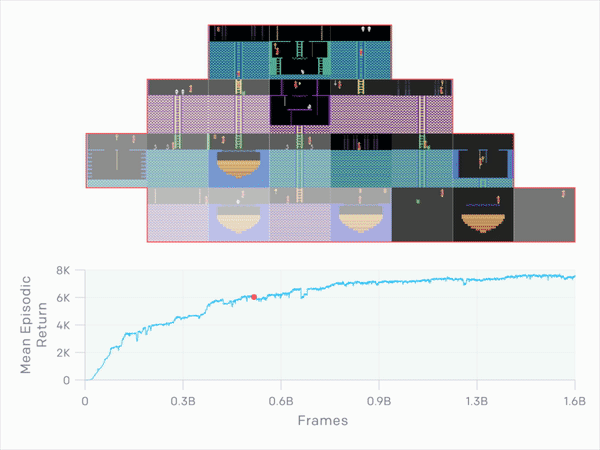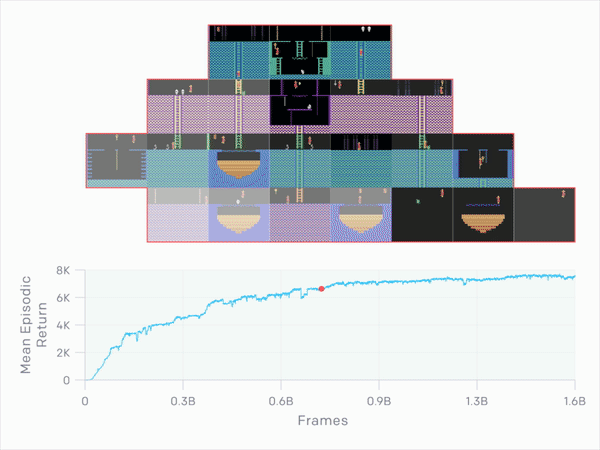
The goal of RND is therefore the development of artificial intelligence, which, instead of focusing on achieving the goal, also tries to do it in the best possible style. This is evident after repeated attempts at Super Mario (discovering 11 levels and hidden locations), although it is not the best when playing Pong. Then the AI decides to extend the game indefinitely.
Also read: People, however, are superior to OpenAI Five in DOTA 2
Source: VentureBeat
Related posts:
 The OpenAI robot learns dexterity through virtual training
The OpenAI robot learns dexterity through virtual training  The Russians developed active camouflage for people and vehicles
The Russians developed active camouflage for people and vehicles  IBM of the NYPD is developing AI to search for people by race
IBM of the NYPD is developing AI to search for people by race  This audio system puts the music straight into your ears
This audio system puts the music straight into your ears  Logitech Z333 2.1 speaker system test
Logitech Z333 2.1 speaker system test  The new Buzzraw X series of retro electric bikes was presented
The new Buzzraw X series of retro electric bikes was presented



