




Intel Arc A380 (Xe HPG) Test
: Test |CUP | Specs |Config
How good is Intel Arc? The test of an imported Arc A380 from China provides answers to this question even without a sample from Intel. The entry-level model had to prove itself against the GeForce GTX 1650, Radeon RX 6400 and 6500 XT. In addition to the pure performance in games, massive driver errors turned out to be another big issue.
Intel’s first gaming graphics card under test
It is not uncommon for complex hardware developments to appear later than initially thought. However, it is not the rule that it degenerates like Intel’s Arc series gamer graphics cards based on the Alchemist architecture.
Intel just won’t let Arc out there, at least not really. Because Arc already exists in notebooks and as a discrete graphics card. But only the very small mobile variants are available in homeopathic doses in this country, the rest are exclusively and officially only available in China. In countries outside of China, however, Intel still does not want to talk too much about the products. That might only change with the faster models in the form of the Arc A750 or Arc A770. When they will appear is ultimately apart from “2. Half of 2022” still unclear.


Gunnir Arc A380 Photon 6G Test : ein China-Import
The situation is currently not very satisfactory for players and editors outside of China, because Intel only samples the press there. For inquisitive minds, the motto is personal initiative.
The editors were inquisitive and imported a Gunnir Arc A380 Photon 6G from China via a roundabout route to Intel. When the company was informed of this, there was still the obligatory “Reviewer’s Guide”, but its press department was unable to contribute anything other than the current public driver.
The test thus represents the current status of the Arc platform in the desktop PC, as players in China or those who import the product from there will find it. It remains to be seen to what extent the situation will change before the official start in Europe.
Intel Arc A380 vs. RX 6400, RX 6500 XT und GTX 1650
The Arc A380 is an absolute entry-level graphics card with a rumored MSRP of $125-$150 before taxes – Gunnir’s custom design sells for the equivalent of $150 in China. Two weeks ago, the editors paid 203 euros including shipping in China, but excluding shipping to Germany and any customs duties.
It’s not for nothing that Intel is pitting them against a Radeon RX 6400 from AMD – and it’s already a good deal slower than the already slow Radeon RX 6500 XT (test). The graphics card would have absolutely no chance in the normal test course, so the editors have set up a completely new one in which the A380 has to prove itself against the Radeon RX 6400 and the Radeon RX 6500 XT from AMD and the GeForce GTX 1650 from Nvidia. All benchmarks were recalculated for this article.

Not surprisingly, the focus is on the gaming performance, but the usual other measurements such as power consumption, temperature and volume are also examined. In addition, there is a brief excursion into ray tracing and the video units will also play a role. Right at the start, the currently simply disastrous state of the driver should not go unmentioned.
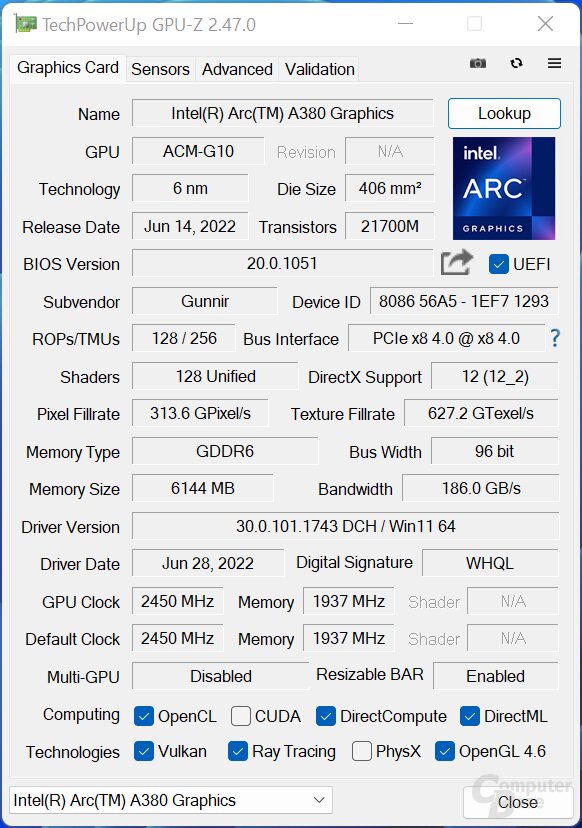
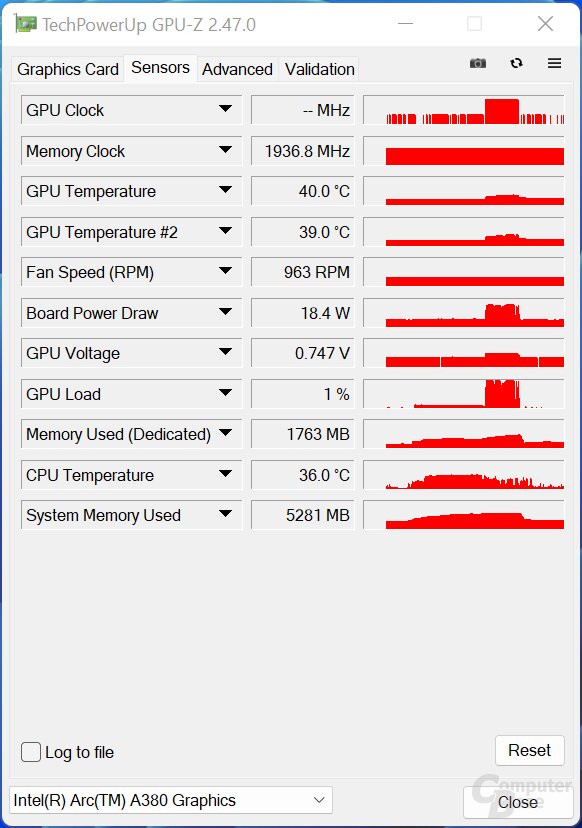
GPU-Z with the Intel Arc A380
Bild 1 von 3

Intel Arc A380: The key data in detail
To date, Intel has not given any deep insights into the Alchemist architecture. Instead, the early, but at least official, details about Xe-HPG are the current state of affairs. At least the configuration of the Arc A380 tested here is now official.
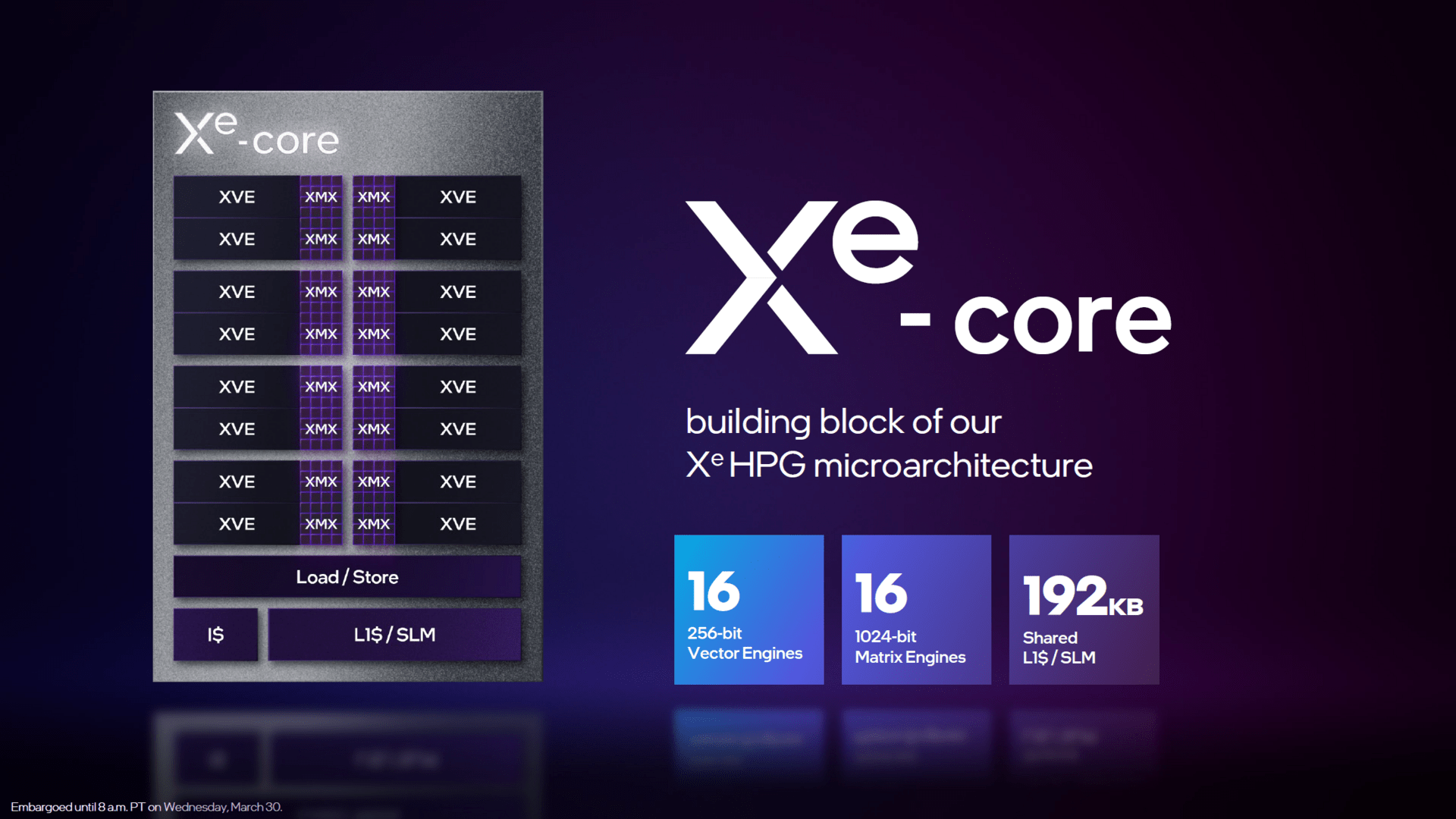
It is based on the ACM G11 GPU manufactured by TSMC in the N6 process and is therefore the smaller of the two Alchemist chips. There is no official information on the transistor budget and the chip size, but the rumor mill speaks of 7.2 billion and 157 mm², which would mean a surprising number of transistors on a surprisingly large area. AMD’s Navi 24 (notebook as well as Radeon RX 6400 and 6500 XT) is also based on 6 nm and has only 5.4 billion transistors and an area of 107 mm² – but does not offer a video unit either.
The Arc A380 uses the maximum expansion of the GPU with 2 render slices, a total of 8 Xe cores and thus 128 vector engines. The larger ACM-G11 chip, on the other hand, is based on 8 render slices and thus up to 512 vector engines. Intel still hasn’t specified what a Vector engine can do exactly, but considering the speculated 1,024 ALUs, an Xe core would consist of 128 FP32 ALUs, which corresponds to the structure of Nvidia Ampere (AMD RDNA 2: 64). Since an Xe-Core holds 16 vector engines, each of them would in turn consist of 8 ALUs. The Vector engines support “Rapid Packed Math” with the formats FP16 and INT8.
Also not official, but from the preliminary information on Alchemist there are 8 texture units per Xe-Core, so ACM-G11 would be able to fall back on 64 of them. Additionally, there are 16 ROPS per render slice for a total of 32 on the Arc A380. A 192 KB L1 shared cache is available for each Xe core. The L2 cache that ties the 2 render slices together is 4MB.

Intel Alchemist (Bild: Intel)
Bild 1 von 4


Raytracing: Closer in Nvidia than in AMD
The number of eight ray tracing units on the small chip is official again, and thus one per Xe core. These can accelerate ray traversal, triangle intersection and bounding box intersection, so that the separate RT units are based on Nvidia’s RT structure and should be superior to AMD’s current offshoots in RDNA 2. For example, they do not create the BVH structure (“Bounding Volume Hierarchy”), this part is taken over by the normal FP32-ALUs instead.
In turn, Nvidia’s RT units also take care of creating the complete BVH structure (Excursion: Raytracing in games VI: How rays from GPUs are accelerated), part of which is what Intel calls the bounding box intersection calculation. It is currently still unclear whether Intel’s RT core, like Nvidia’s RT core, takes care of the complete creation of the BVH structure.
Machine learning is accelerated with separate units
The total of 128 XMX matrix units for matrix acceleration is also official. These functional units compete with Nvidia’s tensor units. Each Vector unit has its own XMX unit, on which Intel’s own upsampling technology XeSS will be accelerated in the future. Intel is still keeping details about XeSS under wraps.
What is known is that an MX unit can perform 128 FP16/BF16, 256 INT8 or 512 INT4/INT2 calculations per cycle. In the FP16 format, the XMX units can thus perform four times as many calculations per cycle as the normal arithmetic units using DP4a instructions and sixteen times as many as without DP4a – although for the MXM units they must be available as matrices.

MXM Matrix Unit for Machine Learning (Image: Intel)
Bild 1 von 2

ACM-G11 can access a 96-bit wide memory interface, the memory expansion is 6 GB (12 GB is theoretically also possible, but such a model does not exist). The PCIe interface supports eight lanes of the 4.0 standard on the small GPU.
The Xe Media Engine for all important codecs
All Arc graphics cards come with a media engine (video decoder and encoder) that can encode and decode all current codes with H.264, H.265, VP9 and AV1. Only Intel Alchemist can encode AV1 in hardware so far.
Intel speaks of up to 8K60 12-bit HDR when decoding and up to 8K 10-bit HDR when encoding. Apparently, the encoding only works with a maximum of 30 FPS. “Popular video software‘ is supposed to support the Xe Media Engine, whatever programs it may be dealing with. Handbrake and BlackMagic DaVinci Resolve Studio 18 are definitely among them.

With DisplayPort 2.0 but without HDMI 2.1
Alchemist’s display engine has a few surprises in store. In addition to DisplayPort 1.4a, DisplayPort 2.0 UHBR10 is already supported. DisplayPort is correspondingly far advanced, while HDMI lags behind: there is no more than version 2.0b.
When it comes to the resolutions and refresh rates, Intel can then give very high numbers, taking DisplayPort 2.0 into account, and speaks of two times 8K60 HDR and four times 4K120 HDR.

Deep Link can partially combine dGPU and iGPU
With the help of “Deep Link”, the Arc graphics cards can work together with iGPUs from Intel as long as they correspond to the Xe series, which has been the case since the 11th generation Core. dGPU and iGPU can work together on compute and machine learning algorithms under the name “Deep Link Hyper Compute” and increase the encoding performance under the name “Deep Link Hyper Encode”. In order for this to be possible, the software used must explicitly support “Deep Link”.
Related posts:
 7-nanometer Nvidia GPU, TSMC will handle most of the production
7-nanometer Nvidia GPU, TSMC will handle most of the production  ASRock X299, a new BIOS allows you to install 2 TB of memory
ASRock X299, a new BIOS allows you to install 2 TB of memory  MSI Prestige X570 Creation Review: Test | Specs | Hashrate
MSI Prestige X570 Creation Review: Test | Specs | Hashrate  Radeon RX 5500 XT, PCI Express 3.0 castrates performance?
Radeon RX 5500 XT, PCI Express 3.0 castrates performance?  An overclocker ran 1TB of RAM on an X299 motherboard limited to 256GB
An overclocker ran 1TB of RAM on an X299 motherboard limited to 256GB  Best Review 2021: MSI MPG X570 Gaming Edge WiFi Under $250 ($200)
Best Review 2021: MSI MPG X570 Gaming Edge WiFi Under $250 ($200)



