




During last week’s event Intel Architecture Day, the company showed different variants of the company’s upcoming graphics cards based on the new architecture Xe. Among these was the data center-focused product family Xe-HP, designed for high scalability in capacity depending on application. Then Intel showed a graphics circuit that applies a computing device or tile.
Just a few days later, it’s time for the Hot Chips technology fair, where Intel’s graphics manager Raja Koduri shows off the top configuration of Xe-HP. Here, four tiles are combined on one and the same graphics circuit. The four tile units are interconnected via Intel’s EMIB technology, which enables different circuits on the same surface to communicate with each other. This technology is probably also used to let the tile units’ HBM memory communicate and share data with each other, but this does not appear in Intel’s presentation.
Raja Koduri does not go into deeper technical details in his presentation, but instead takes the opportunity to reveal exciting details about how the graphics cards will be able to scale in terms of performance. With just one tile unit, floating point performance in FP32 format of 10.6 TFLOPS is achieved. When the step is taken to two tile units, the result grows to 21.2 TFLOPS, an increase that is stumbling close to a doubling. For floating point calculations with single precision, the result is 42.3 TFLOPS.
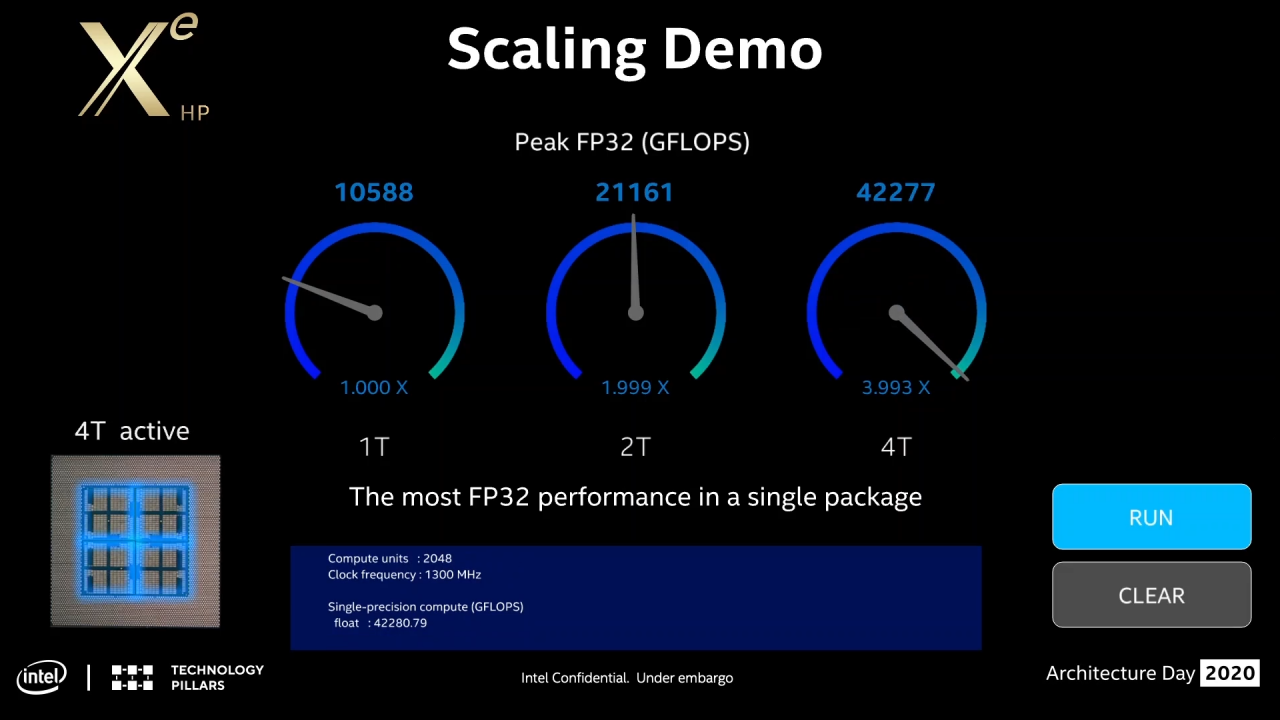
With four tile units, a crazy 41.9 TFLOPS is reached, which in turn is stumbling close to four times faster than the basic configuration. With this, Intel demonstrates that the company’s graphics cards in the Xe-HP family are linearly scalable, and performance gains will thus increase linearly with the number of tile units the graphics cards are equipped with. This can be compared with the competitor Nvidia, which with the data center product A100 instead combines several graphics cards in the server product HGX A100 to scale performance.
Nvidia’s A100 is based on the new graphics architecture Ampere and, according to the company’s information, reaches an FP32 performance of 19.5 TFLOPS per graphics card. Against this background, Intel’s promised performance of over 41 FLOPS on a graphics card with four Xe-HP tiles looks undeniably promising. Raja Koduri also mentions that Xe-HP has the capacity to achieve petaflop performance, that is, over 1,000 TFLOPS for specific AI calculations. However, the specifications shown in Intel’s presentation speak of a significantly lower result.
The presentation mentions that the Xe-HP with four tile units is equipped with a total of 2,048 calculation units (EU) that run at a clock frequency of 1.3 GHz. The EU units are capable of acting as tensor cores and perform 128 calculations and two FMA additions per clock cycle. A summation of 2,048 × 128 × 2 gives the result 524.3 TFLOPS for AI calculations. This suggests that the plan is for Xe-HP to be able to run at clock frequencies exceeding 2 GHz, which would provide computing power in the petaflops class.
However, Intel has not yet revealed when the graphics cards with this top configuration can reach the market. If this happens within the coming year, the company is expected to stand up well to competitors. If it takes longer than that, the balance can instead weigh in favor of the competitors. Xe-HP represents Intel’s second highest performance level, with Xe-HPC being the highest level with supercomputers and ex-scale calculations in mind.
Read more about Intel Xe:
Related posts:
 Review & Test: Video card Gigabyte GeForce RTX 3060 Ti Gaming OC Pro
Review & Test: Video card Gigabyte GeForce RTX 3060 Ti Gaming OC Pro  AMD Radeon RX 5600 XT VS GTX 1660 Ti and RTX 2060: Review| Set-up| Hashrate
AMD Radeon RX 5600 XT VS GTX 1660 Ti and RTX 2060: Review| Set-up| Hashrate  Review of the KFA2 GeForce RTX 3060 Ti Core video card
Review of the KFA2 GeForce RTX 3060 Ti Core video card  GIGABYTE GeForce RTX 3090 Gaming OC video card: Review| Specs | Set-up|
GIGABYTE GeForce RTX 3090 Gaming OC video card: Review| Specs | Set-up|  INNO3D GeForce RTX 3090 iCHILL X4 video card review: Test | Config | Hashrate
INNO3D GeForce RTX 3090 iCHILL X4 video card review: Test | Config | Hashrate  ROG Strix GeForce RTX 3070 OC Review: Test | Specs | Hashrate
ROG Strix GeForce RTX 3070 OC Review: Test | Specs | Hashrate



